由于出行限制和在家办公的普及,包含声音的Telepresence远程呈现最近引起了社区极大的兴趣。所述技术一般需要一个麦克风阵列来捕获会议室中的声音,并在远程位置播放双耳信号。会议室可能包含噪音或干扰,所以有必要增强信号。另外,会议参与者和可穿戴阵列可能会改变位置,从而对处理和播放造成挑战。
目前的远程呈现方法通常采用双耳阵列或球形阵列来编码双耳信号,从而有助于高质量的双耳再现。信号增强同时可以合并以抑制干扰说话人或噪声。然而,在多个移动说话人和/或移动阵列的情况下,设备的性能会恶化。同时,手持设备或可穿戴阵列可能无法提供双耳和球形阵列。总之,当前的方法有以下局限性:一般配置的麦克风阵列无法合并;动态和嘈杂的场景会导致性能显著下降。
在名为《Audio Signal Processing for Telepresence Based on Wearable Array in Noisy and Dynamic Scenes》的论文中,以色列本·古里安大学和Reality Labs Reaearch的研究人员提出了旨在克服当前限制的解决方案。相关措施包括三个阶段:声场景分析,即使用DPD测试估计混响下的说话人方向;基于期望源和阵列传递函数估计的信号增强;以及使用双耳信号匹配方法再现双耳信号。
团队研究了两种替代方案:第一种是基于模型;第二种方案采用了基于学习的语音分离方法,以支持动态条件下的一致增强。最后,实验通过听力测试来量化主观表现。
论文提出的三级系统主要用于根据麦克风信号估计pl、r(f)。所述系统的两个版本因学习水平不同而有所不同。第一个系统主要基于模型,并结合了光谱和空间学习,第二个系统在场景分析阶段结合了深度学习说话人分离方法,从而支持动态场景。
所述两个版本如图1所示。
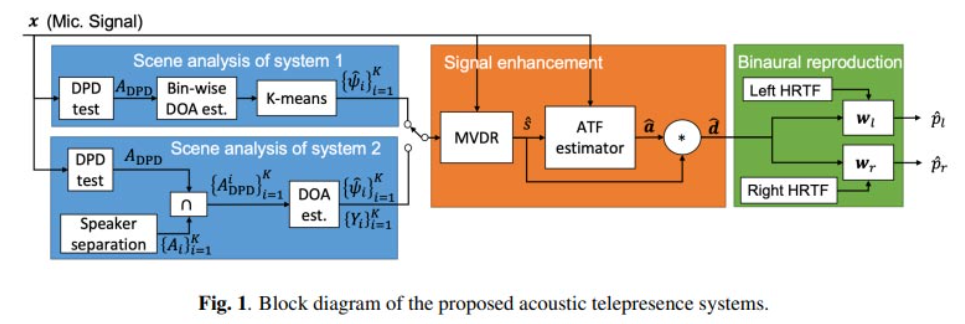
系统1–基于模型的处理
场景分析:在第一阶段,使用基于DPD测试的方法估计说话人的DOA(对混响具有鲁棒性)。这一系列的函数在时频(TF)域中运行,并通过仅使用TF bins克服混响。
信号增强:在第二阶段,假设一个期望的说话人,估计期望的信号d(f)。对于多个期望的说话人,可以对每个说话人重复以下步骤,同时相应地定义d(f)和u(f),然后将每个期望的说话人的贡献相加。
双耳再现:在最后阶段,使用双耳信号匹配(BSM)方法估计pl,r(f)。使用这种函数,根据期望的麦克风信号dˆ(f)估计pl,r(f)。
上述系统最适合静态场景。为了支持动态条件,通常需要多个说话人追踪算法。但由于所述函数仅依赖于DOA估计,当DOA估计不可用时,它们的性能可能会随着非活动语音周期(说话人在未发声时移动)而下降。
系统2–扩展的说话人学习
为了克服当前追踪方法的局限性,团队在第一阶段中加入了一个语音分离网络,其使用STFT域中的掩码来分离说话者。说话人TF掩码由网络估计,用于将每个TF bin(DOA估计)与特定说话人相关联。与当前说话人追踪函数提供的估计说话人关联不同,提议的关联基于光谱信息。因此,它可以不受非活动语音周期的影响。说话人分离网络的输入是单个麦克风信号的频谱图,输出是TF掩码Mi(t,f),i=1…,K。
接下来,研究人员进行了模拟研究,以评估在包括可穿戴阵列、期望和不期望的说话人以及噪声的场景中,每个拟议系统阶段的性能。特别地,其研究了再现双耳信号的质量以及估计说话人关联对信号增强的影响。
一个会议场景包括混响室中的两个说话人(期望的和非期望的),以及安装在眼镜的麦克风阵列。为了检验提议的关联,团队模拟了说话人在时间实例t=5时的位置交换。这种位置交换要求系统适应新的和即时的说话人位置,这可能发生在非活动语音段之后。
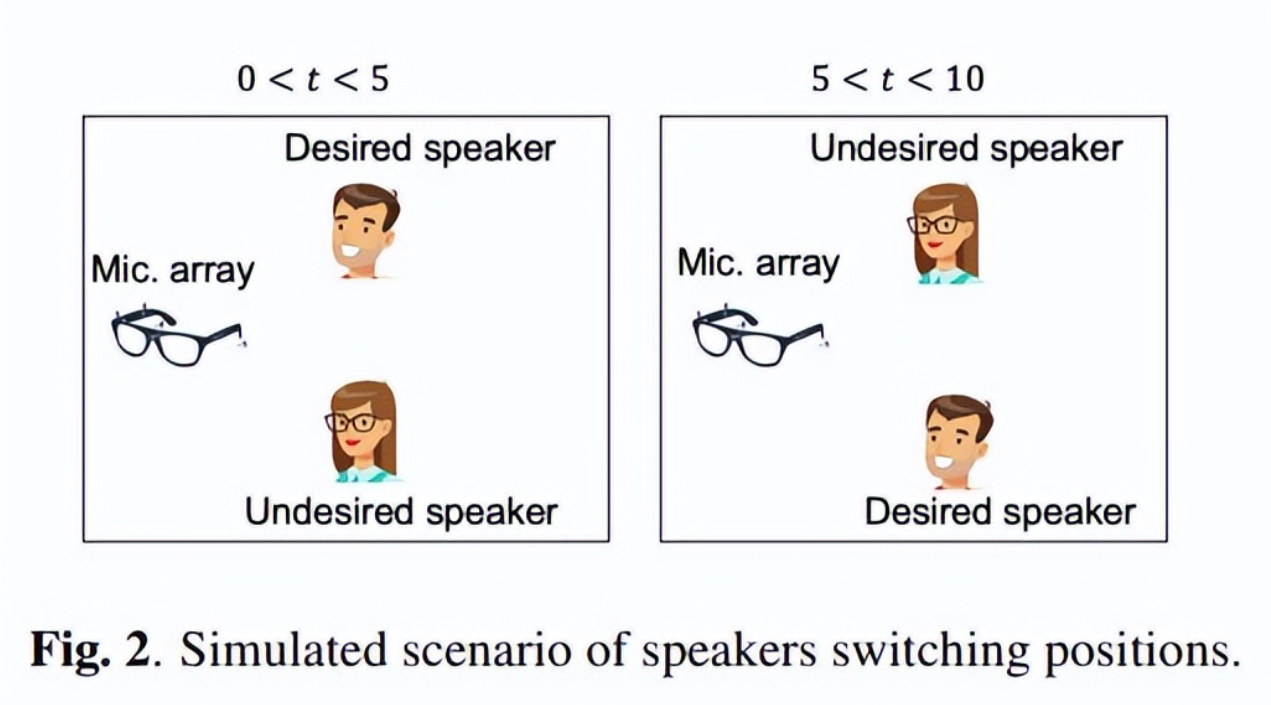
模拟场景如图2所示。房间大小为10×15×3米,混响时间约为0.5秒。图3所示的阵列用于记录最近的EasyCom数据集。在本研究中,仅使用传声器1-4进行处理,传声器5和6处的信号作为参考双耳信号,传声器5和6的转向矢量作为HRTF。作为1020个方向数据集的一部分提供的阵列导向向量从48 kHz降采样到16 kHz。将阵列放置在(x,y,z)=[3,5,1.7]米的位置,将说话人放置在距离阵列2.5米的位置,高度相同,方位角为±45度。
然后,使用图像法模拟说话人位置对阵列的脉冲响应。对于wsj0-2mix数据集的10秒男性和女性语音片段,以16 kHz的频率采样,并与对应于所需和非所需说话人位置的房间脉冲响应进行卷积。通过切换脉冲响应模拟说话者的位置交换。

对于实验结果,表1给出了方位估计和估计d时的归一化均方误差(NMSE)。表1显示,两个系统在05时的NMSE较低。这一结果表明,所提出的方法可以处理不活动扬声器的动态场景。
团队随后进行了两次听力测试,以研究该系统的增强和双耳复制阶段,以及采用MUSHRA协议的多重刺激。2名女性和7名男性被试参加了这两项测试。第一个测试通过比较BSM方法和双声道再现的性能来检查再现阶段。BSM处理的麦克风信号和环境音信号是使用上述模拟场景生成,仅包括位置交换前的所需信号部分。N=9阶的高阶双频(HOA)信号用于呈现参考信号。另外两个测试信号是使用一阶双频(FOA)信号呈现,有和没有MAGL。图4上图描述了结果。如图所示,使用MagLS和参考,BSM的评级接近FOA,并且比FOA好得多,这表明使用4麦克风阵列的拟议方法可以获得高质量的双耳信号。
第二个测试检查增强阶段。所有四个测试信号都是在位置交换后使用上述模拟生成。将使用所提议的系统获得的增强双耳信号与参考信号和锚定信号进行比较。图4下图的测试结果显示,系统2运行良好,而系统1出现故障。这是由于错误的联想,这导致增强了非期望的说话者。
相关论文:Audio Signal Processing for Telepresence Based on Wearable Array in Noisy and Dynamic Scenes
总的来说,团队主要提出并研究了解决所述挑战的三阶段系统。仿真研究和听力测试表明,所提出的方法应用于眼镜阵列可能有所帮助。